Hello,
Welcome to the 42nd issue of TMPDIR Weekly, a newsletter covering Embedded Linux, IoT systems, and technology in general. Please pass it on to anyone else you think might be interested and send any tips or feedback to our forum or news@tmpdir.org.
Thanks for reading!
Khem and Cliff
Linux
Parallelism in Yocto Builds
Yocto project can massively parallelize the builds by not only issuing parallel
compile jobs (typical -jN settings via
PARALLEL_MAKE
in make terminology), but it can compile many components in parallel courtesy
BB_NUMBER_THREADS.
There are a few other variables which can be effective in defining parallel
build behavior as described in
speeding up a build.
These settings have to match the CPU/Memory/IO resources of underlying build
machine, otherwise it can result in
obscure failures
which are hard to pin-point.
The upcoming release codenamed langdale will have a new feature in bitbake
which can scale the task issuing dynamically based on threshholds for
CPU/IO/Memory pressures.
Determining thresholds for build system is still going to be left to user but
there is now support in bitbake to scale the build parallelism dynamically is a
welcome change
Yocto project Package Tests (ptest)
The Yocto project has this immensely useful feature which enables cross testing
packages. It's called ptest and is orchestrated by the ptest-runner tool.
This tool installs client tools into the image, which help in running and
collecting results of the tests. It's easy to use with qemu based machines, and
is well
described
in Yocto project documentation. A lot of packages are already creating ptest
packages when this feature is enabled, and there are
sample images
available in the Yoe Distribution as well to see ptest in action.
IoT
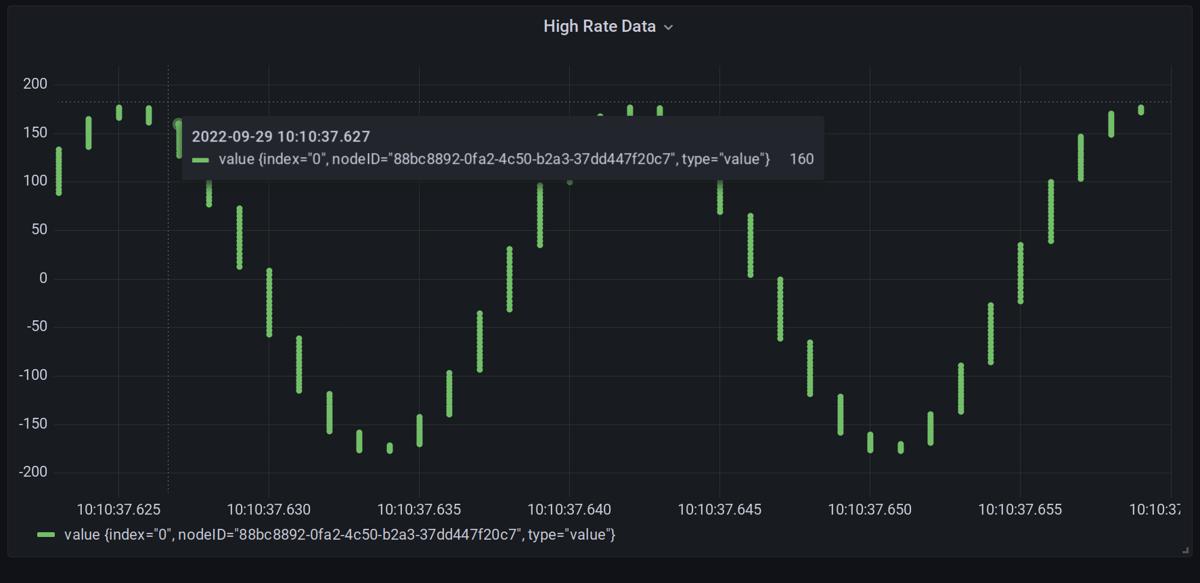
High rate (15KHz) Data
Working on adding a signal generator to add high rate simulated data for a project I'm working on. This is an interesting performance problem and ended up creating a separate set of NATS subjects for hr (high rate) data. This seems reasonable as you'll typically process high rate data with some algorithm (RMS, average, etc) before running through a rule or other logic -- for example the Influx DB client consumes and stores HR data so it can be viewed. However, I then learned that Grafana and the Influx DB UI only support MS resolution (as shown below), so we need a different graphing solution for high rate data.
More efficient Hashing algorithms
While re-implementing the SIOT upstream support on top of SQLite, the question has come up -- can we implement a more efficient hashing algorithm? Perhaps one that can be updated incrementally as new data comes in. It turns out the bitwise XOR operation has this property. So it seems if we hash bits of data with something like a CRC-32, then we can incrementally update the Hash as new data comes in. See above link for more details.
Other
Changelog Podcast with James Long
James Long (author of Actual Budget and Prettier) appeared on the Changelog podcast recently to discuss why he open sourced Actual Budget. This is a very interesting discussion and covers a number of business, development, and OSS issues.
Embrace Constraints
A nice discussion on the benefits of constraints. Many times we may tend to think “if only I had this resource, time, more developers, etc.” In the end, because you don’t have all the resources in the world, you will probably build a better product.
Quote for the week
Example has more followers than reason. -- Christian Nestell Bovee
Thoughts, feedback? Let us know: info@tmpdir.org.
Join our Discourse forum to discuss these or new topics. Find past issues of TMPDIR here. Listen to previous podcasts at https://tmpdir.org/.